I haven't blogged in a while, and it's been bothering me. My DITA (Digital Information Technologies and Architecture) module ended in December, and I wasn't sure what to add to my blog after that. If you've read this before you will know that setting up a blog was a requirement for that module of my course. It's now a new term and having had three lectures about Web Applications, it feels the logical way to go. Over the last few weeks we've covered HTML and CSS. I won't be posting about them as I have already covered the basics in previous posts. I will, however, recommend a few good websites at the end of this post.
This blog post is going to be about my first experiments with PHP. To begin, I should probably give a little bit of background on the topic. PHP is a programming language which is used in dynamic web pages. Unlike static html web pages, dynamic web pages are flexible, they can 'remember' you, and are generally easier to maintain and update. PHP stands for 'Hypertext Preprocessor'. Our lecturer Pete informed us that this is a recursive acronym (another example of geek humour), although it is interesting to note that it orignally stood for 'personal home page' back in 1994 when it was created by Rasmus Lerdorf.
The great thing about PHP is that you can drop it in the middle of HTML script, and it does something wonderful. It is a scripted language and was designed specially for the Web. It is server side, which means everything PHP does occurs on the server rather than on the client. Luckily for me, my university has provided me with a web server application (Apache) so that everything will work.
PHP is open source and platform independent, which means that it is free (hurrah!) and will run with Windows, Macs, Linux, and pretty much anything else. Using a server-side script is great for developing dynamic pages, as I mentioned before. This means that you can do seemingly basic things, like adding in today's date and time, which you cannot do with HTML. It also saves you from repeating yourself when you are coding, which you often have to do using HTML. In the example I use below where I list a number of years in a form, it only takes one piece of PHP code. To do it in HTML I would have to include every single year (which would be 112 lines of script). It would also be more awkward to update. PHP allows you to automate tasks, saving you lots of effort.
PHP also allows you to do some more sophisticated things. For example, you can require conditions to be met before certain content is displayed. It also allows you to store data separately (for example in an SQL database - more on that in another blog post). PHP also allows you to put headers and footers on web pages consistently, send emails, read web pages... hopefully by now it is evident that it is very handy to use.
Having considered why PHP is useful, we can look at how to identify and use it. To add a PHP code to a page, use php tags:
<?php
?>
This is the PHP equivalent to the HTML tags <html> and </html>. To see some PHP in action, please see my web page here. I'm not sure whether non-students can access this, so apologies if you can't see it. One day I may have my own web page which everyone can see. But for the time being, this is where I have a space online.
At the top of the page it tells you the current day, date and time. The PHP code for this is:
<?php
echo "<p>Today is " . date("l") . " " . date("d") . date("S") . " " . date("F") . " " . date("Y") . ". It is " . date("g") . "." . date("i") . " " . date("a") . ".</p>";
?>
All the different letters after date describe what will be brought back. so 'l' is the day, 'd' is the date, etc. Be aware that PHP is case sensitive, so typing date("s") and date("S") will give different results. PHP date documentation explains this very well. The echo command inserts content into the HTML page.
Note the use of quotation marks. If the text you wish to include contains quotation marks, this can cause an error. For example, if you wanted to display 'He said "good morning".' then you would probably type:
echo "He said "good morning."";
However this would cause an error message because computers aren't all that bright and won't understand that you have quotation marks within quotation marks. To tell it that this is what you are doing, you must use a backslash to precede the quotation mark like this:
echo "He said \"good morning.\"";
This is better than mixing single and double quotation marks (which would fix your problem but could potentially cause you more bother in the long run).
After displaying the date on my web page I tried to be more ambitious and involve some drop-down menus. On the page there is a field for day, month and year. Before anyone points out the obvious, I know that you can select non-existent dates (such as 31st February). Automatically selecting days that match months requires Java and I haven't got that far yet!
I will divide this up into chunks, because different code is required for the different parts. The day and year are integers (numbers) so the code is essentially the same. It looks like this:
<label for="day">Day</label>
<select name="day" id="day">
<?php
$day = 31;
for ($counter = 1; $counter <= $day; $counter++) {
echo "<option>".$counter."</option>n";
}
?>
</select>
Take note that this is a mixture of HTML script and PHP. As I said before, PHP is great because it can be dropped in. All you have to remember is to start php with <?php and end it with ?>
The third line of PHP includes a 'for' command. This is what I was referring to earlier when I said that PHP allows you to automate tasks, and when it requires a condition to be met. What the code is saying is that the variable name $day is 31. When the variable $counter, which starts at 1, is less than or equal to the variable $day, display the number in the counter and add 1 to the counter. The code in the curly brackets { and } populates the drop down menu with 1, then when the semi-colon is reached it loops back to the beginning of the 'for' command. In doing so, the drop down menu becomes 2 (1+1), then 3 (2+1), then 4 (3+1) and so on until the condition is met where $counter becomes equal to $date, which is when it reaches 31. Then it stops looping back to the beginning of the 'for' command and moves on to the next piece of code after the semi-colon (in this case it moves on to the month which I will discuss next).
The code for the month is a little bit more complicated because it involves arrays. An array is a container for strings (words or letters), integers, or a mixture. It is used to create a list for the computer to read through. I will discuss this below before I get on to the month drop down menu.
Arrays
In programming, arrays are used to create lists in a labelled 'container'. An array is a collection of related data, in the example of months it would be a list of all of the months. When selecting an item from an array, it is important to understand that the computer starts counting from 0, not from 1. So to select the third item in a list, you would need to use [2] and not [3]. The function count() allows you to see how many items are 'stored' in your array.
Additionally, you can label the items within your array. So rather than calling back numbers, you can select a label. For example, if you were looking up meetings in a calendar you might have something like:
$meeting = array("client" => "Bloggs & Co.", "room" => "Conference Centre", "subject" => "Discussion re: new contract");
So rather that using the position of the item in the array, you could just type in:
$meeting["client"]
which would return "Bloggs & Co.". The terminology for the items is that on the left (client) is the index and on the right (Bloggs & Co.) is the value.
So, after that slight deviation let us return to the date on the web page. The coding for the month field is:
<label for="month">Month</label>
<select name="month" id="month">
<?php
$month = array("January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December");
for ($counter = 0; $counter <= 11; $counter++) {
echo "<option>".$month[$counter]."</option>";
}
?>
</select>
With all the of the field code, don't forget that it will need to be within a form. So if you are trying this out yourself, you will need to start with:
<form>
<fieldset>
Then put your HTML and PHP code here to generate the drop down menus. Then close with:
</fieldset>
</form>
I hope this has been a useful, if brief, introduction to PHP. It's easy to see why it is a popular language to use, as you can do so much more with it than you can with html on its own. Not to mention the fact that it saves you from typing potentially thousands of lines of nearly-identical code using functions like 'for'.
Some useful links:
HTML and CSS Tutorials by HTML Dog
W3 Colour selector for CSS
Code Academy
PHP Guidance
Books that I will be using during this module:
Griffiths, P. (2007) HTML Dog: The Best-Practice Guide to XHTML & CSS, New Riders: Berkeley, CA
See this on Amazon
Ullman, L. (2011) PHP and MySQL for Dynamic Web Sites: Visual QuickPro Guide (Visual QuickPro Guides), Peachpit Press: Berkeley, CA
See this on Amazon
Negrino, T. & Smith, D. (2012) JavaScript: Visual QuickStart Guide (Visual QuickStart Guides), Peachpit Press: Berkeley, CA
See this on Amazon
Sunday, 12 February 2012
Sunday, 8 January 2012
Web 2.0 as a collaborative tool
Introduction
This blog will outline the background of Web 2.0, discuss its use as a publishing tool using the Internet as a platform and explore its potential in relation to developing technologies. While Web 2.0 is closely related to the semantic web and the growing openness of the Internet (sometimes referred to as ‘Web 3.0’), this is outside the scope of this blog and will not be covered.
The term ‘Web 2.0’ was first used by O’Reilly Media, Inc. in 2004. There has been confusion regarding a definition, as the use of ‘2.0’ sounds like a software upgrade. In fact, Web 2.0 was a term originally used to distinguish Internet companies that had survived the dotcom bubble bursting in 2001. O’Reilly (2005) used 6 headings to define Web 2.0:
1. The Web as Platform
2. Harnessing Collective Intelligence
3. Data is the Next Intel Inside
4. End of the Software Release Cycle
5. Lightweight Programming Models
6. Software above the Level of a Single Device
Since then, O’Reilly has emphasised that ‘the network is the platform’, and that ‘the cardinal rule is... users add value’ (KamlaBhatt, 2007). In others words, collaboration is central to the concept of Web 2.0. It is important to distinguish between Web 2.0 and social networking websites; Web 2.0 is both the platform on which technologies and sites have been built, as well as a space for user-generated content (UGC), rather than the social networking sites like Facebook and Twitter, which are built upon the platform (Cormode & Krishnamurthy, 2008).
This blog will explore three themes, with an emphasis on social networking websites. First, it will discuss the Internet as a platform, including publishing information. Second, it will consider digital data representation, and current use and future potential for information scientists in central government. Finally, it will investigate the latest Web 2.0 technologies and concepts, reflecting on their impact in the digital environment.
Publishing Information
As indicated above, the Internet (or network, or Web) is the platform. This means there is no longer a requirement to have specific software or a particular machine to access the same content. This is why, for example, both Mac and Windows users can utilise Facebook, Twitter, Flickr, and other Web 2.0 sites. This has opened up accessibility to a much wider user-base, as it is no longer necessary to program in HTML to publish to the Web because these sites provide an interface. The OECD suggests that this has democratised publishing on the Internet with a rise of ‘amateurs’ (Vickery & Wunsch-Vincent, 2007). In addition, Xu et al (2010, p.9) indicate that ‘the Web is becoming a useful platform and an influential source of data for individuals to share their information and express their opinions’. This sharing of opinions has changed the dynamic of publishing information, from the one-to-many ‘push’ of Web 1.0 to a many-to-many collaborative environment in Web 2.0.
The user-base of Web 2.0 sites is wider still due to technological advances in recent years. People can now use mobile phones, as well as tablets and laptops to access the Internet. As O’Reilly (2005) states in his definition of Web 2.0, this represents software above the level of a single device. It is possible to access information anywhere with an Internet connection. Additionally, it is easier to publish information on the go, as well as consume it. Most Internet-capable phones and tablets have cameras and facilitate the capture and sharing of information by users with Web 2.0 publishing tools. A common example of this is people sharing holiday photos instantly on Facebook and Twitter.
Blogging websites are publishing tools, and have become increasingly popular. Blogs, such as Blogger, enable users to post online using a familiar interface. While there is the option to write in HTML, many people simply use the text box and formatting buttons (see Fig 1). Several central government departments use blogs on their intranet sites. The Department for Business, Innovation and Skills uses the blogging tool in SharePoint, with senior staff and teams providing updates on their work via a blog. This is an effective way of publishing information, as all staff members have access and can use tools on the intranet to comment and provide feedback. An additional benefit is that no further training is required to use the software, as the interface is familiar to staff. As it is hosted on the intranet, it is accessible to all users as it is possible to apply personalised settings to profiles on their PCs, and to Internet Explorer, which is the browser used to access the SharePoint intranet site.

Fig 1 – the blogging interface on Blogger
A further advantage to blogging is the wide availability of tools, and the ability to create professional-looking web pages with ease (Evans, 2009). Blogs are used by businesses and professionals, looking to publish information. These bloggers also use other Web 2.0 sites, such as Twitter, to capture a wider audience for their blog and to promote their business. A recent survey demonstrated that ‘almost all Professional Full Timers (93%) and Professional Part Timers (91%) us[e] Twitter’ (StateOfThe Blogosphere, 2011). Using multiple Web 2.0 sites allows professionals to push their information efficiently and easily.
Representation of Digital Data
Formerly, users who wished to publish content on the Internet needed an understanding of programming, such as using HTML to publish a web page. With Web 2.0 technologies, this is no longer a requirement as websites provide an interface. An example of this is the use of Yammer, a social networking tool, by a central government department to encourage its staff to work collaboratively. Maness (2006) argues that Web 2.0 ‘is not a web of textual publication, but a web of multi-sensory communication.’ This is the way in which Yammer is used by civil servants; they can publish their ideas, and can also give and receive feedback interactively. It also enables them to promote other people’s ideas by sharing links to other pages, such as news articles and publications. The web is no longer being used purely as a ‘push’ medium, but has been ‘transformed into a dynamic network harnessing creativity and collective intelligence’ (Fraser & Dutta, 2008, p. 2).
This provides a good opportunity for information scientists in government. The use of blogs and wikis allows them to organise their information in an accessible way, giving users the option to add their own folksonomies to optimise information retrieval. O’Reilly (2011) describes this exploitation of web applications as harnessing ‘collective intelligence’, which was one of his definitions of Web 2.0 in 2005. Information scientists could potentially use applications to try to capture information and understand ways of working within their organisations. Using Web 2.0 technologies offers information professionals a great advantage, as they can build applications to cater to their users’ needs. The advantage of this is that, unlike some information systems used, applications tend to be intuitive thus reducing the requirement for training for users. The use of applications also allows information professionals to address ‘one size fits all’ software, such as forcing an Electronic Documents Records Management (EDRM) system on users. It is possible to hide the EDRM system behind a Web 2.0 interface, which can be more easily adjusted to users’ needs. For example, some government departments are looking at implementing a more user friendly SharePoint interface to document management systems, while maintaining the underlying EDRM system to allow information specialists to apply information management policies, such as access controls and retention and disposal rules, behind the scenes.
Central government departments are not the only public service using Web 2.0 technologies to share information. Mitchell (2011) describes how the Deputy Chief Constable from Tayside Police encourages his staff to ‘tweet on the beat’. This creates both a challenge and opportunity for information scientists; the challenge will be to stay on top of the amount of information being published by users, and to try to keep information organised and presented in a meaningful way. These websites do offer some methods of organising information, such as Twitter lists which allows you to create a stream from the users in that group. The advantage of this is an accessible representation of digital information, which offers real-time information for Twitter users, externally and within the organisation. The disadvantage of relying on Twitter would be a loss of control, as information specialists would not easily be able to apply retention schedules, or ensure digital continuity without capturing Tweets and storing them on an internal system. This raises some integrity issues; for instance, context may be lost if police staff include links to external sites which are not captured. Furthermore, the use of Twitter raises the question of ownership and security; the Twitter terms and conditions make it clear that while information posted is your responsibility, they are granted a royalty- free licence to ‘use, copy, reproduce, process, adapt, modify, publish, transmit, display and distribute’ it (Twitter, Terms of Service). In this environment it is important that information specialists provide clear guidelines for staff using Web 2.0 services, to address these risks, although this is no guarantee that they will be adhered to.
Recent Advances
Technological developments have allowed these Web 2.0 applications to flourish. When Tim Berners-Lee first imagined the World Wide Web, he claims that he envisaged the interactive environment that is now associated with the term Web 2.0 (Laningham, 2006). The evolution of information and communications technology (ICT) has made it possible for people to use wikis, blogs, social networking, and the other applications described as Web 2.0. A noteworthy difference is that the use of these technologies has changed the way that people work. Fraser & Dutta (2008) suggest that while organisations are vertical hierarchies, networks are horizontal by nature. This leads to the conclusion that using Web 2.0 applications will enable people to cross these hierarchical divides and work together without barriers. To refer back to the example of government using Yammer, members of staff have noticed that people are no longer working in silos, and are consulting colleagues at all grades across the department, as the use of social networking tools has allowed them to locate people with expertise efficiently. The use of an online digital environment has empowered staff to work flexibly and capably.
Furthermore, a recent study by the University of Melbourne suggests that browsing online, increases productivity within an organisation. Coker (2011) established that those who participated in workplace Internet leisure browsing (WILB) had significantly higher productivity than those who did not. A Socialcast infographic also demonstrates the balance between connectivity and productivity in Europe (see Fig 2) with the use of social networking websites (Dugan, 2011).
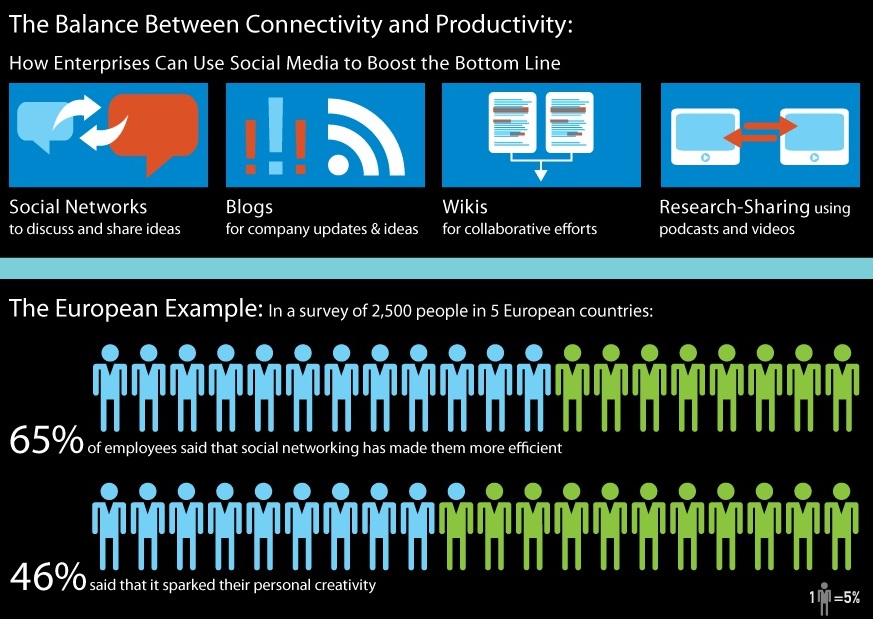
Fig 2 – Infographic showing the effect of social networking on employees in Europe
Looking to the future, there is a relatively new technology which could have a significant impact on information specialists: cloud computing. This has been defined as ‘a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources...’ (Mell & Grance, 2011). Many companies already use a similar model to this, as EDRM Systems retrieve data from a central server. Cloud computing goes further, as the software and data are all stored online and computers are used to access an online environment in which to work. Cloud computing relates back to O’Reilly’s concept of software above the level of a single device, as it provides software as a service (see also Luftman & Zadeh, 2011). The challenge for information professionals is to exploit and add value to this transition to decentralised information systems, as it will require a difference level of support for users. Other implications to consider will be the amount of control information professionals have over systems – for example, if a local EDRMS is replaced by a central cloud where information is stored, how will it be organised? How easy will it be to control access, and to maintain information integrity?
Conclusion
This blog has explored the use of Web 2.0 as a method for publishing digital information. The first conclusion that can be drawn from the examples outlined is that the ability to publish information with the Internet as a platform, as described by O’Reilly in his definition of Web 2.0, has opened up accessibility to information for a wide variety of people. Individuals, groups and companies can easily publish and use digital information. The example of blogging demonstrates how Web 2.0 tools and sites are enabling people to access and share information proficiently.
Second, online information is accessed in a different way; previously information was ‘pushed’ by publishers on read-only web pages. Web 2.0 websites encourage user interaction, indicating that information is used more dynamically, allowing ideas to develop in a creative, collaborative space; O’Reilly’s concept of collective intelligence. This blog has observed the importance of information scientists in this environment, to offer methods of organising and measuring the value of the vast quantity of information published and absorbed online. Specialist skills will continue to be valuable to meet these challenges and exploit potential uses of Web 2.0 technologies.
O’Reilly’s definition of Web 2.0 as software above the level of a single device was discussed. Technological developments have allowed people to remain connected almost limitlessly, using applications on mobile devices to publish and read information online, facilitating efficient information-related tasks, such as streaming Tweets and sharing links. This blog has looked to the future to evaluate the usefulness of Web 2.0 technologies going forward. Arguably, a significant change will occur as use of cloud technologies is adopted by individuals, businesses and public services.
It is difficult to draw a conclusion about the impact Web 2.0 technology will have on the information profession as a whole, but it can be said with some certainty that information will continue to need organising and maintaining however it is presented and accessed by users. Information professionals will not necessarily be managing information in the traditional sense, acquiring, cataloguing and distributing it, but they will move forward as application developers, database managers and advisers on legislation and best practice as users take more control over publishing, organising and using information.
Bibliography
Aharony, N. (2008) “Web 2.0 in U.S.
Aharony, N. (2011) “Web 2.0 in the professional LIS literature: An exploratory analysis” Journal of Librarianship and Information Science 43(3)
Anderson, P. (2007a) What is Web 2.0? Ideas, Technologies and Implications for Education (JISC: Bristol) Available at: http://www.jisc.ac.uk/media/documents/techwatch/tsw0701b.pdf [Accessed 02/12/2011]
Anderson, P. (2007b) “`All That Glisters Is Not Gold' -- Web 2.0 And The Librarian” Journal of Librarianship and Information Science 39(4)
Blogger. Accessed at: www.blogger.com [Accessed 17/12/11]
Coker, B. (2011) “Freedom to surf: the positive effects of workplace Internet leisure browsing” New Technology, Work and Employment 26(3)
Cormode, G. & Krishnamurthy, B (2008) “Key differences between Web 1.0 and Web 2.0,” First Monday 13(6) [Accessed *date*] Available at: http://www.uic.edu/htbin/cgiwrap/bin/ojs/index.php/fm/article/view/2125/1972 [Accessed 29/11/11]
Dugan, L. (2011) ““No Tweeting!” How Restricting Social Media At Work Affects Productivity [INFOGRAPHIC]” MediaBistro.com Available at: http://www.mediabistro.com/alltwitter/restricting-social-networks-at-work_b15379 [Accessed 23/12/11]
Evans, M.P. (2009) “The Aggregator Blog Model: How a Blog leverages Long Tail Economics,” Journal of Information Science and Technology 6(2)
Facebook. Available at: www.facebook.com [Accessed 15/12/11]
Flickr. Available at: www.flickr.com [Accessed 15/12/11]
Fraser, M. & Dutta, S. (2008) Throwing sheep in the boardroom [electronic resource]: how online social networking will transform your life, work and world (Chichester : Wiley)
KamlaBhatt (2007) Tim O'Reilly on What is Web 2.0? Available at: http://www.youtube.com/watch?v=CQibri7gpLM [Accessed 15/12/11]
Laningham, S. (ed.) (2006) Tim Berners-Lee. Podcast, developerWorks Interviews, 22nd August, IBM website. Available online at: http://www.ibm.com/developerworks/podcast/dwi/cm-int082206.txt [Accessed 18/12/11]
Luftman, J. & Zadeh H.S. (2011) “Key information technology and management issues 2010–11: an international study”. Journal of Information Technology, 26(3)
Maness, J. (2006) "Library 2.0 Theory: Web 2.0 and Its Implications for Libraries". Webology, 3(2), Article 25. Available at: http://www.webology.org/2006/v3n2/a25.html [Accessed 29/11/2011]
Mell, P. & Grance, T. (2011) The NIST Definition of Cloud Computing (Draft): Recommendations of the National Institute of Standards
Mitchell, C. (2011) Trust Me, I’m a Follower. Comms2point0 Available at http://www.comms2point0.co.uk/comms2point0/2011/12/7/trust-me-im-a-follower.html [Accessed 12/12/2011]
OReilly, T. (2005) What Is Web 2.0: Design Patterns and Business Models for the Next Generation of Software Available at: http://oreilly.com/pub/a/web2/archive/what-is-web-20.html?page=1 [Accessed 17/12/11]
O'Reilly (2011) Web 2.0 Summit 2011: John Battelle and Tim O'Reilly, "Opening Welcome" Available at: http://www.youtube.com/user/OreillyMedia?feature=relchannel#p/c/E7E5EFF32BE55315/3/KhGTp-wymj4 [Accessed 15/12/11]
StateOfThe Blogosphere (2011) “State of the Blogosphere 2011: Introduction and Methodology” Technorati Available at: http://technorati.com/blogging/article/state-of-the-blogosphere-2011-part2/page-2/ [Accessed 15/12/11]
Twitter. Available at: www.twitter.com [Accessed 30/12/11]
Vickery, G. & Wunsch-Vincent, S. (2007) Participative Web and User-Created Content: Web 2.0, Wikis and Social Networking (Paris
Warr, W. (2008) “Social software: fun and games, or business tools?” Journal of Information Science 34(4)
Xu, G., Zhang, Y. & Li, L. (2010) Web Mining and Social Networking : Techniques and Applications. Web Information Systems Engineering and Internet Technologies Book Series 6 1st Edition. (New York: Springer)
Yammer. Available at: www.yammer.com [Accessed 15/12/11]
This blog post is available online at: http://kaysafus.blogspot.com/2012/01/web-20-as-collaborative-tool.html
Wednesday, 7 December 2011
Information Architecture
In our final DITA lecture we considered web site design; more specifically information architecture. We considered what makes a good web site by considering what end users love and hate about the web. Our lecturers listed the following:
| Love | Hate |
|---|---|
| Good Design | Can't Find it |
| Aesthetics | Gratuitous Bells and Whistles |
| Big ideas | Inappropriate Tone |
| Utility | Designer-Centredness |
| Findability | Under-Construction |
| Personalisation | No attention to detail |
| Waiting |
Much of this is common sense - for example, people will get frustrated if they cannot find what they need, or if they are overwhelmed with unnecessary graphics. I have certainly been irritated in the past by websites that make you watch (or click a button to skip) a video before going to the main site - especially if you intend to use it a lot.
We considered why it is important to organise information. For you info pros out there, the answer is incredibly obvious, but for the sake of argument let's spell it out. Not organising your information might seem quicker when you create it. A common cry where I work is 'why can't we just put things in our personal drives and be done with it?' The reason is twofold: first, when you come to look for something it will be like searching for a needle in a haystack. Second, if it's on your personal drive, we can't help you as much, because we can't see it. (I risk digressing here to the importance of a nice EDRMS in an organisation, so perhaps I will move on.) If this argument doesn't work, one can point to financial reasons - Jakob Nielsen was quoted in Rosenfeld and Morivlle's book 'Information Architecture' saying, 'low intranet usability costs the world economy $100 billion per year in lost employee productivity' (p.xii). This was back in 2002, so nearly a decade later I suspect this figure is a lot larger.
Organising information on web pages is actually very flexible. For example, it is possible (although perhaps not recommended!) to link an unlimited number of pages. In the 'real world' it is more difficult to do this; if you compare information architecture to architecture (buildings), you would not be able to link a room to an infinite number of rooms. A database is slightly different, as entity relationships tend not to link to a very large number of other entities. (This is due to the requirement for unique identifiers; other tables get added in - see the database blog for more details on this!)
Above we looked at a list where web loves and hates were identified. So how do we avoid falling into these traps? A cynical response, perhaps, is to not let the graphics design team get over excited(!) However, our lecturer pointed out that another trap people fall into is handing over the website design to the geeks, who make it over-technical. To avoid this when developing a web site, it is important to have people from lots of backgrounds on the design team, including: graphic design, technical types (for dealing with databases, programming, etc), project managers and information architects. Information architects generally have a background in information management - for librarians it can be a natural move as it is basically creating a structure, providing labels and making things organised.
When you've got your team you need to consider how you are going to achieve the web loves listed above (and avoid the web hates!). There are lots of guides on the web describing how to put together a good web site (for example, Smashing Magazine and Sharpened Productions). A common theme is to be user focused. It seems obvious, but think about who is using your website, why they are using it, and how they might use it. A general rule of thumb is to avoid making people think too much; navigation should be intuitive. This is where good architecture comes in. An information architect considers the relationships between pages, optimises access to information and of course will know all about indexing! In addition, they will be familiar with consistent labelling, for example not mixing up their nouns and verbs.
So what can we conclude? Good web design isn't just about having lots of graphics and helpful information (although this is still important!). With the expansion of the Web people are increasingly impatient and fast-moving, so good navigation systems and searchable web pages are a must. People visiting your web page shouldn't be forced to think too much, which is possible with consistent labelling. (To think about it another way, people shouldn't be scrutinising your labels too closely, they should just be using them).
Organising information on web pages is actually very flexible. For example, it is possible (although perhaps not recommended!) to link an unlimited number of pages. In the 'real world' it is more difficult to do this; if you compare information architecture to architecture (buildings), you would not be able to link a room to an infinite number of rooms. A database is slightly different, as entity relationships tend not to link to a very large number of other entities. (This is due to the requirement for unique identifiers; other tables get added in - see the database blog for more details on this!)
Above we looked at a list where web loves and hates were identified. So how do we avoid falling into these traps? A cynical response, perhaps, is to not let the graphics design team get over excited(!) However, our lecturer pointed out that another trap people fall into is handing over the website design to the geeks, who make it over-technical. To avoid this when developing a web site, it is important to have people from lots of backgrounds on the design team, including: graphic design, technical types (for dealing with databases, programming, etc), project managers and information architects. Information architects generally have a background in information management - for librarians it can be a natural move as it is basically creating a structure, providing labels and making things organised.
When you've got your team you need to consider how you are going to achieve the web loves listed above (and avoid the web hates!). There are lots of guides on the web describing how to put together a good web site (for example, Smashing Magazine and Sharpened Productions). A common theme is to be user focused. It seems obvious, but think about who is using your website, why they are using it, and how they might use it. A general rule of thumb is to avoid making people think too much; navigation should be intuitive. This is where good architecture comes in. An information architect considers the relationships between pages, optimises access to information and of course will know all about indexing! In addition, they will be familiar with consistent labelling, for example not mixing up their nouns and verbs.
So what can we conclude? Good web design isn't just about having lots of graphics and helpful information (although this is still important!). With the expansion of the Web people are increasingly impatient and fast-moving, so good navigation systems and searchable web pages are a must. People visiting your web page shouldn't be forced to think too much, which is possible with consistent labelling. (To think about it another way, people shouldn't be scrutinising your labels too closely, they should just be using them).
Saturday, 3 December 2011
Mobile Information, the Semantic Web and the World of Open
Hello bloggees! My apologies for having fallen off the map of late, I have been very busy trying to get some reading done for my coursework. I know, excuses, excuses, but I am going to attempt to catch up on what's been happening in my DITA module in this post, which covers Web 2.0 technologies, potential Web 3.0 and related policy.
First of all, I will give you a quick overview of mobile information. Then I will touch on the semantic web, which is sometimes considered as 'Web 3.0'. I will conclude with a look at the world of open - this covers open source systems and open data.
Mobile Information
Mobile devices offer the advantage that they are context aware, By this, I mean that they can identify where they are. This includes, but is not limited to GPS (Global Positioning System) on mobile devices. Having GPS allows your phone to offer map services and you can find companies near to where you are. Additionally, mobile devices often have a magnetic compass an accelerometer which means that the phone 'knows' which way it is facing.
Having cameras in your mobile device can also allow context awareness. Face and building recognition technology is inaccurate, but it is improving. If you combine this with GPS, you could add more detailed metadata to your photographs: in theory you could tag where, when and who you are photographing.
Bluetooth also offers context awareness on mobile devices. Bluetooth allows devices to receive information, and also to broadcast, for a distance of about 10 metres. It has been proposed as a technology for 'information fountains' - for example offering tourist information in the vicinity of attractions.
One downside to mobile devices is their size; the screens are very small (certainly considering the size of the screen on a laptop or PC). Applications are therefore stripped of some of their content so that they can be viewed on a smaller screen. Usually the same content is presented, but in a different or collapsed way. For example, if you open a Wikipedia page on a mobile device the information has been collapsed into menus so the loading time is smaller, and you do not have to scroll through a lot of information unnecessarily. Keyboards on mobile devices are also small - this can cause problems as fiddly keys lead to spelling mistakes and a reduced typing speed. This can be avoided to an extent on some devices, as there is the option to have different keypads for different applications.
The Semantic Web
The Semantic Web is one vision of what Web 3.0 might be like. While there is no fixed definition of Web 3.0 (some argue that it is merely a marketing plug) it is generally assumed that it will need to be one step further than Web 2.0. So if Web 1.0 was readable, Web 2.0 was readable and writable, Web 3.0 should be readable, writable and executable (or interact-able). The semantic web offers a way of doing this.
As we know, computers aren't that bright on their own. Unlike people, they are not intuitive and require strict instructions to execute. If you think about XML, this 'tells' the computer more information than HTML. The semantic web is a lot like this. However, it goes further than XML which only 'tells' the computer that something is a title; it also explains what a title is. An example of semantic web technologies is RDF or the Resource Description Framework.
At it's most basic, RDF creates metadata. But it also creates meta-metadata. An RDF statement is made up of a subject, an object and a predicate. The subject is the thing itself - for example it could be an image, a journal article, a video, and so on. The object is the metadata, the predicate is the relationship. For example:
Subject: this video
Object: Matt Damon
Predicate: has starring actor
Typically the subject is a URL (which makes sense as we are discussing Internet resources). Sometimes, the predicate and object are also URLs. However, these URLs need not point to anything specific - they could be URIs (Unique Resource Identifiers). Unlike a URL, URIs do not necessarily point to a tangible 'thing' on the Internet. A predicate that is a URI will describe the relationship - for instance in the example above rather than just saying 'has starring actor', it will explain to the computer unequivocally what this actually means so that it can be 'understood'.
From this you can build a map of relationships of Web Ontology Language (OWL). This is a taxonomy with rules applied in a sort of web. This allows the computer to make links that you might not have been able to spot yourself, especially if you have a lot of information in the OWL. So using the example above perhaps you could look at all the videos that have Matt Damon as a starring actor, and you could map his career. Perhaps this is not the most useful thing you could do with an OWL but hopefully you get the idea!
The World of Open
In this lecture we considered open access publishing, open source software and open data. It was reiterated that the Internet is a disruptive technology, and has caused a change in the way people interact with information. It is unlikely that the replication and distribution of digital information would have been so widespread without the Internet.
The world of open is as much an ideological idea as a technical one. There are academics and programmers who are passionate about removing barriers to openness, including digital publishing, source code, government information, and so on.
Open access publishing is where full research articles are available to anyone for free, across the web. The impact of open access on the publishing world is debateable. There is an obvious advantage to using journals which are free for immediate access, but these journals have not been around long enough to build up a reputation. The real impact of open access publishing remains to be seen.
Open source software development looks to develop an infrastructure rather than finished products for commercial sale. The Internet has made is possible for software developers webwide to work collaboratively, uniting programmers with similar areas of interest regardless of where they are. In particular the Internet makes asynchronous working possible, as developers can communicate via email, for example.
In our lecture we discussed the motivation for Open Source Software; after all, it seems odd to be offering software structures for free! There are two types of stakeholders to consider, at micro and macro level. At micro level, developers may be building this software because it doesn't exist and they need it. There is also a financial incentive as individual developers can build a reputation and make a lot of money if their products are used widely. At a macro level, Open Source allows developing and maintenance costs to spread across several companies (this can also work with individuals).
Finally, I should touch on Open Data. The best way to look at this is with an example. The British Government have run several initiatives over the last few years, which are all driving at openness. The Freedom of Information Act (2000) requires departments to have a publication scheme, which is a list of available documents/information. Usually, departments are quick to publish released information after a request. The first initiative was Making Public Data Public, which was championed by Tim Berners-Lee and the Minister for Digital Britain, The Rt Hon Stephen Timms MP. Over time (and under various governments!) the openness agenda has been referred to by several names, and has branched out (at the moment it is unclear whether there is a huge different between Open Data and Transparency), but the underlying message is the same: public data should be made open and available for use unless there is a good reason not to release it. The idea is that the default should be openness, rather than only releasing certain data. Naturally there is still a lot of work to be done, but there is already an awful lot available here and here.
This concludes a rather brief overview of some Web 2.0 technologies and related policies. It will be interesting to see what happens next. Mobile technology is developing at a rapid pace (despite the latest iPhone exploding a few times) and it will be interesting to see what is dreamed up next. The semantic web and open data go together well, and I think they will perhaps develop together.At Cabinet Office they are already using semantic web technology on their Transparency website.
Sunday, 13 November 2011
Web Services and APIs
Like this on Facebook. Read my Twitter feed. Have a look at the Google map below to see where we are. These are the kind of statements that web users are getting used to in a Web 2.0 environment. Usually, however, not a lot of thought goes into how these buttons and feeds are actually integrated into web pages. However, this is what we discussed this Monday in our DITA lecture.
APIs provide an interface, without any requirement for technical understanding of what goes on in the background, thereby reducing the need for technical understanding. The ideal is that people will be able to create APIs with no programming background whatsoever. Our lecturer described APIs as an underlying pillar of Web 2.0. APIs (generally it is agreed that this stands for Abstract or Application Programming Interface) are programming tools. PC Mag (no date) describes what APIs are and how they work:
A web service is a type of API. O'Reilly (2009) states that 'a web service is any piece of software that makes itself available over the Internet and uses a standardized XML messaging system'. A web service, as the name implies, is a service (software) which is available over the Internet. Web services use the same technology as web pages (the client-server relationship), and it even looks a bit like HTML because XML uses tags. However, web services are content only - unlike web pages there is no structure to an XML document. Additionally, where web pages are designed to be read by humans, web services are designed to be read by machines.
While XML means eXtensible Markup Language, it is not actually a language. Instead, it provides conventions for creating your own language with tags; it is sometimes described as a meta language. As it is not strictly a language, there is no international standard; to quote Pirates of the Caribbean, 'the code is more what you'd call "guidelines" than actual rules.'
An example of APIs
Let's say I don't understand the way that Facebook works, but I want to let people 'like' my page. The nice people at Facebook have put the code on the web so that you can do just that. I have done so, on my 'mash up' web page here. It is unnecessary to understand exactly what the code means, because it works. Although, if you are interested the coding you need is:
<div id="fb-root"></div>
<script>(function(d, s, id) {
var js, fjs = d.getElementsByTagName(s)[0];
if (d.getElementById(id)) {return;}
js = d.createElement(s); js.id = id;
js.src = "//connect.facebook.net/en_GB/all.js#xfbml=1";
fjs.parentNode.insertBefore(js, fjs);
}(document, 'script', 'facebook-jssdk'));</script>
<script>(function(d, s, id) {
var js, fjs = d.getElementsByTagName(s)[0];
if (d.getElementById(id)) {return;}
js = d.createElement(s); js.id = id;
js.src = "//connect.facebook.net/en_GB/all.js#xfbml=1";
fjs.parentNode.insertBefore(js, fjs);
}(document, 'script', 'facebook-jssdk'));</script>
Then where on your web page you want the code to appear you need to add:
<div class="fb-like" data-href="http://www.student.city.ac.uk/~abkb846/public_html/MashUp.html" data-send="true" data-width="450" data-show-faces="true"></div>
You can put this on any web page, the only bit you need to change is the URL, which I have made bold above. The script above is a bit confusing for humans to read, but easy for machines to understand. It is 'asking' Facebook to run its 'Like' process on the web page, without the owner of the web page needing to understand how Facebook does this in the first place. The Facebook API is the interface which allows applications to communicate with each other (usually without the awareness of the user at all).
Conclusion
To sum up, the use of APIs could potentially open up programming to users, as the need for coding knowledge is reduced. APIs are incredibly useful for social media as they are great for communication. They open up communication between different programs and allow people to improve functionality of web sites.
Conclusion
To sum up, the use of APIs could potentially open up programming to users, as the need for coding knowledge is reduced. APIs are incredibly useful for social media as they are great for communication. They open up communication between different programs and allow people to improve functionality of web sites.
O'Reilly Media (2009) Top Ten FAQs for Web Services. Available at http://www.oreillynet.com/lpt/a/webservices/2002/02/12/webservicefaqs.html [Accessed 7 November 2011]
PC Mag (no date) Definition of API. Available at http://www.pcmag.com/encyclopedia_term/0,2542,t=application+programming+interface&i=37856,00.asp#fbid=9qFJ8KQn0H3 [Accessed 7 November 2011]
PC Mag (no date) Definition of API. Available at http://www.pcmag.com/encyclopedia_term/0,2542,t=application+programming+interface&i=37856,00.asp#fbid=9qFJ8KQn0H3 [Accessed 7 November 2011]
Wednesday, 2 November 2011
Some thoughts on Knowledge
There has been a bit of debate about what ‘knowledge management’ actually is. Some argue that it is the same thing as information management, whereas others see it as something different. The usual distinction is that knowledge is in people’s heads, whereas information is recorded.
TS Eliot
Where is the Life we have lost in living?
Where is the wisdom we have lost in knowledge?
Where is the knowledge we have lost in information?
(Choruses from The Rock, 1934)
The 'Eliot' model separates knowledge from information thus:

In our lecture, we discussed as a group what the pyramid could represent. There was a general consensus that, in this model, wisdom comes from knowledge, which in turn comes from information, which comes from data. The best way to represent this is to use an example.
120
This is data. On its own, how useful is it?
It is 120 miles to Birmingham from London.
This is information, which is arguably more useful than the data.
It is 120 miles to Birmingham, and the quickest route by car is to take the M40.
This is knowledge, which builds upon the information.
It is 120 miles to Birmingham, and the quickest route by car is to take the M40. However, if you are travelling during a busy period you might do better taking the train!
This is wisdom, which builds further on the knowledge.
So how does one acquire knowledge and wisdom with this model? Can it be shared? There was some debate about this. We eventually decided that wisdom seems to come with experience, and we couldn’t easily establish whether it could be shared – can someone else’s experiences become our wisdom, or is it then only knowledge or information? This theory states that you can share knowledge – people can write it down, for example. There are those who do not subscribe to this theory, and argue that tacit knowledge cannot be passed on...
Karl Popper
Here we are going to dip a toe into the rather big pool of philosophy, and look at Popper’s worlds as states of information. I will try to simplify this if I can. He argued the case for three worlds:
- ‘Real’ physical World
- Inner World, our subjective, personal view
- Communicable Information between the two, or the sum total of worlds 1 and 2
This has been a very brief thought, and I’m still not decided on knowledge management. It strikes me as a very difficult area, as knowledge is not a tangible thing – it’s difficult to measure, to value or even to prove whether it’s there. For now, I’ll finish with a video which I think demonstrates the difficulties involved in knowledge sharing. It’s a bit of fun really – 'expert' gamers trying to teach non-gamers how to play Battlefield. Be warned – it does contain some bad language and violence (as well as heavy product placement!).
Sunday, 30 October 2011
The World Wide Web and HTML
My blog, Information Overload!, can be accessed at http://kaysafus.blogspot.com/
My webpage, Using HTML, can be accessed at http://www.student.city.ac.uk/~abkb846/public_html/HTMLindex.html
In this blog I will discuss the World Wide Web (WWW, or Web) and Hypertext Markup Language (HTML) as a technology for the digital representation of information, in relation to Web 1.0. I will examine the technical details with a short background history, before considering the opportunities and limitations of using the Web and HTML.
The Web is not the same thing as the Internet. The Internet is the channel through which the Web can function. Email also uses the Internet as a channel. The Web was designed to link information stored on computers. Tim Berners-Lee, its inventor, worked at CERN and originally designed it to enable him to remember connections between people, computers and projects. His vision was to have a ‘single, global information space’ (Berners-Lee, 1999, p. 5). Specifically, his solution was to use hypertext to allow users to move between documents. In his proposal, Berners-Lee offered the solution of a ‘universal linked information system’ (Berners-Lee, 1990). He developed HTML as the primary language for web documents, allowing users to instruct browsers how to display content on a webpage using tags (Chowdhury, 2008).
HTML works by using tags to inform the Web browser how information is to be portrayed on the page. A tag is enclosed in triangular brackets, for example <HTML> informs the browser that this is where the HTML begins, and </HTML> informs it that the HTML ends. I have created a website which demonstrates some of the different tags available.
The term Web 1.0 describes the Web in its early stages, when it was primarily designed to display and share information, rather than allowing users to add their own content, for example by contributing to wikis. Early webpages tended to be rather plain, and merely displayed information and provided hyperlinks to relevant documents elsewhere on the Web. Over time, presentational tags were developed to improve the appearance of webpages, which I will discuss later.
The Web and HTML provide a number of opportunities for the representation of information. It was designed to end incompatibility between different computers (Berners-Lee, 1999). Webpages can be viewed on different machines, presenting information consistently, and allowing users to view and navigate between information in the same way. This is still important today with a huge range of devices and programs used to access the Web. The Web and HTML have been applied to share information globally effectively in all manner of fields, including Information Science. Most webpages use navigation with hyperlinks to assist users, such as guidance on using the catalogue and on Information Management policies on the National Archives webpages here.
Using HTML is fairly simple; therefore it is popular (Chowdhury, 2008). Unlike other computer languages, HTML is in plain English and does not require users to have an in-depth knowledge of programming. Unlike more complex technologies for representing information, such as using SQL to create databases, HTML offers users an easy method to display and share digital information.
Another reason that HTML can be very useful for information professionals is that it allows metadata tags (or meta tags) to improve the experience for a user without them even being aware of it. For example, adding keywords to a webpage describes the page’s content. Using meta tags effectively can offer powerful navigation and improve information retrieval (Rosenfeld & Morville, 2002).
However, there are also limitations to the Web and HTML. In Web 1.0, HTML was not a multi-lingual language. Many languages use scripts which cannot be represented in standard HTML, because it is ‘based on a very limited coded character set.’ (Yergeau, no date) So for example, the Omniglot webpage uses images to demonstrate Sanskrit writing, which means that users cannot copy and paste characters, or interact with them as easily as with Latin languages.
Additionally, while HTML was originally compiled of elements for describing the structure of information, such as paragraphs, hyperlinks and headings, it evolved to include presentational tags, including fonts, colours and tables. This has been attributed to the introduction of Mosaic (Meyer, 2000). Presentational tags made HTML coding confusing and untidy, and caused interoperability problems (Chowdhury, 2008). This disadvantage of HTML has been recognised, and the World Wide Web Consortium (W3C) introduced a recommendation called CSS. CSS stands for Cascading Style Sheets, and offers rich styling of web documents (Meyer, 2000). This removes the need for tags like <B> (for making text bold). The use of CSS created another opportunity, as HTML can return to its original purpose, which was as a structural language, and the presentational aspect of webpages can be addressed by using CSS. This is useful for information professionals, as it helps to separate out the design aspect. For example, it adds stronger argument that searching is an information specialist area rather than an IT or web design area, as the emphasis is on the structure and content of pages.
I have concluded that HTML and the Web are appropriate technologies for the digital representation of information, in relation to Web 1.0. With my webpage, I demonstrated how HTML tags and hyperlinks can be applied technically for the management of digital information. Today the Information Profession exploits HTML and the Web extensively. In particular, the Web is used for information sharing, for structuring information and for ease of navigation, as demonstrated on The National Archives webpages. Meta tagging is also incredibly useful to information professionals, notably for powerful searching and retrieval functions. HTML is an effective tool to provide access to information because it permits information to be displayed on a range of devices. Furthermore, HTML is relatively easy to learn as it uses plain English and does not require a thorough knowledge of programming, therefore allowing more people to use it.
I investigated the constraints of HTML and the Web as Web 1.0 technologies. I recognised the issue with displaying non-Latin languages as script. This was a problem for basic Web 1.0 webpages; it seems that these could only be represented on a webpage with images, which reduced options for manipulation of information. I highlighted the limitations of tagging, particularly how HTML coding became cluttered with presentational tags. I concluded that this problem became less significant with the introduction of Cascading Styling Sheets, which allowed programmers to separate structural and presentational code.
Berners-Lee, T. (1990) Information Management: A Proposal [online] Available at http://www.w3.org/History/1989/proposal.html [Accessed 22 October 2011]
Berners-Lee, T. (1999) Weaving the Web: the origins and future of the World Wide Web, London: Orion Business
Chowdhury, G. G. and Chowdhury, S. (2008) Organising Information: From the Shelf to the Web, London: Facet Publishing
Meyer, E.A. (2000) Cascading Style Sheets: The Definitive Guide, Sebastopol: O’Reilly Media Inc.
Omniglot (no date) Sanskrit [online] Available at http://www.omniglot.com/writing/sanskrit.htm [Accessed 22 October 2011]
Rosenfeld, L. and Morville, P. (2002) Information Architecture for the World Wide Web, Second Edition. Sebastopol: O’Reilly Media Inc.
The National Archives (no date) Catalogue [online] Available at http://www.nationalarchives.gov.uk/catalogue/default.asp?j=1 [Accessed 22 October 2011]
Yergeau, F. (no date) A world-wide World Wide Web. [online] Available at http://www.w3.org/International/francois.yergeau.html [Accessed 22 October 2011]
Subscribe to:
Posts (Atom)